Kubernetes 中 Pod 的优雅退出机制
Kubernetes 提供了 Pod 优雅退出机制,允许 Pod 在退出前完成一些清理工作。但是如果在执行清理时出现问题,Pod 会正常退出吗?退出需要多长时间?可以指定退出时间吗?系统是否有默认参数?有几个细节是我们需要注意的,本文将从这些细节入手,梳理Kubernetes组件在每种情况下的行为及其参数。
Pod 正常退出
Pod 正常退出是非驱逐退出,包括人为删除、执行错误删除等。
当一个 pod 退出时,kubeletpreStop在删除容器之前执行一个 pod,允许 pod 在退出之前执行脚本来清除必要的资源等。但是,preStop也可能会失败或者挂起,这种情况下preStop不会阻止 pod 退出,kubelet 也不会重复执行,而是会等待一段时间,超过这个时间容器会被删除,以保证整个系统的稳定性.
整个过程都在函数中killContainer。pod优雅退出时我们需要明确的是,kubelet的等待时间是由这些因素决定的,以及用户可以设置的字段和系统组件的参数是如何协同工作的。
宽限期
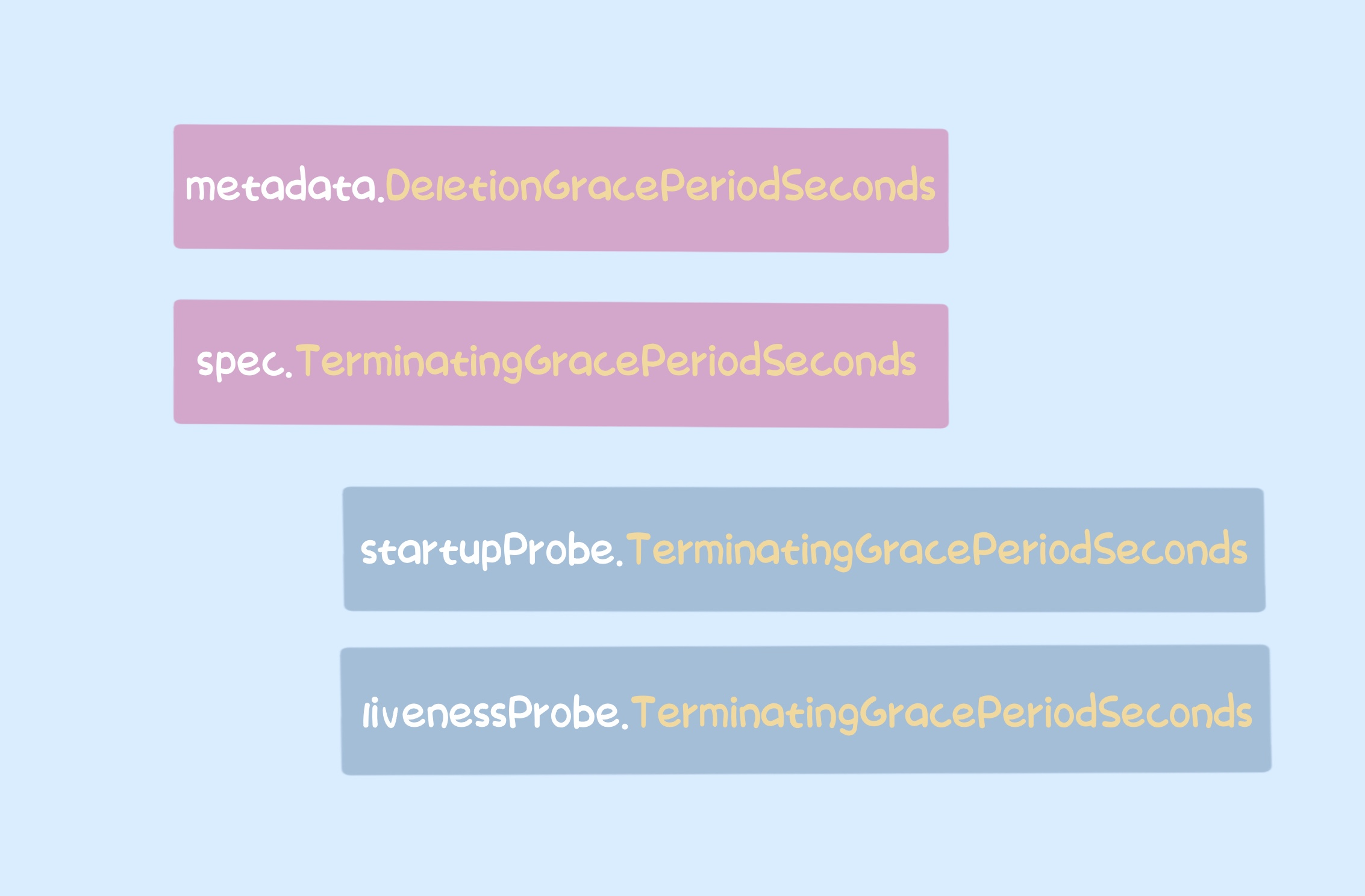
kubelet计算gracePeriod的过程如下
- 如果 pod
DeletionGracePeriodSeconds不是 nil,即被 ApiServer 删除,gracePeriod 直接取值。 - 如果 pod
Spec.TerminationGracePeriodSeconds不是 nil,则查看 pod 删除的原因是什么。- 如果删除的原因是执行失败
startupProbe,gracePeriod 取TerminationGracePeriodSecondsset in的值startupProbe。 - 如果删除的原因是执行失败
livenessProbe,gracePeriod 取TerminationGracePeriodSecondsset in的值livenessProbe。
- 如果删除的原因是执行失败
一旦获取到gracePeriod,kubelet 就会执行pod preStop,函数会executePreStopHook启动一个goroutine 并计算其执行时间。从此时间中减去gracePeriod,以将最终超时传递给运行时以删除容器。超时时间传递给运行时。所以,如果我们设置 pod preStop,我们需要同时考虑 preStop 的执行时间和容器退出的时间,我们可以将 TerminationGracePeriodSeconds 设置为大于 preStop + 容器退出的时间。
func (m *kubeGenericRuntimeManager) killContainer(pod *v1.Pod, containerID kubecontainer.ContainerID, containerName string, message string, reason containerKillReason, gracePeriodOverride *int64) error {
...
// From this point, pod and container must be non-nil.
gracePeriod := int64(minimumGracePeriodInSeconds)
switch {
case pod.DeletionGracePeriodSeconds != nil:
gracePeriod = *pod.DeletionGracePeriodSeconds
case pod.Spec.TerminationGracePeriodSeconds != nil:
gracePeriod = *pod.Spec.TerminationGracePeriodSeconds
switch reason {
case reasonStartupProbe:
if containerSpec.StartupProbe != nil && containerSpec.StartupProbe.TerminationGracePeriodSeconds != nil {
gracePeriod = *containerSpec.StartupProbe.TerminationGracePeriodSeconds
}
case reasonLivenessProbe:
if containerSpec.LivenessProbe != nil && containerSpec.LivenessProbe.TerminationGracePeriodSeconds != nil {
gracePeriod = *containerSpec.LivenessProbe.TerminationGracePeriodSeconds
}
}
}
// Run internal pre-stop lifecycle hook
if err := m.internalLifecycle.PreStopContainer(containerID.ID); err != nil {
return err
}
// Run the pre-stop lifecycle hooks if applicable and if there is enough time to run it
if containerSpec.Lifecycle != nil && containerSpec.Lifecycle.PreStop != nil && gracePeriod > 0 {
gracePeriod = gracePeriod - m.executePreStopHook(pod, containerID, containerSpec, gracePeriod)
}
// always give containers a minimal shutdown window to avoid unnecessary SIGKILLs
if gracePeriod < minimumGracePeriodInSeconds {
gracePeriod = minimumGracePeriodInSeconds
}
if gracePeriodOverride != nil {
gracePeriod = *gracePeriodOverride
}
err := m.runtimeService.StopContainer(containerID.ID, gracePeriod)
...
return nil
}
GracePeriodOverride
在上面的分析中,kubelet在调用runtime接口之前,会判断另外一步gracePeriodOverride,如果传入的值不为null,直接gracePeriod用那个值覆盖之前的。

kubelet计算的主要过程gracePeriodOverride如下。
- 获取 pod 的
DeletionGracePeriodSeconds. - 如果 kubelet 正在驱逐 pod,请使用驱逐设置覆盖 pod 退出时间。
func calculateEffectiveGracePeriod(status *podSyncStatus, pod *v1.Pod, options *KillPodOptions) (int64, bool) {
gracePeriod := status.gracePeriod
// this value is bedrock truth - the apiserver owns telling us this value calculated by apiserver
if override := pod.DeletionGracePeriodSeconds; override != nil {
if gracePeriod == 0 || *override < gracePeriod {
gracePeriod = *override
}
}
// we allow other parts of the kubelet (namely eviction) to request this pod be terminated faster
if options != nil {
if override := options.PodTerminationGracePeriodSecondsOverride; override != nil {
if gracePeriod == 0 || *override < gracePeriod {
gracePeriod = *override
}
}
}
// make a best effort to default this value to the pod's desired intent, in the event
// the kubelet provided no requested value (graceful termination?)
if gracePeriod == 0 && pod.Spec.TerminationGracePeriodSeconds != nil {
gracePeriod = *pod.Spec.TerminationGracePeriodSeconds
}
// no matter what, we always supply a grace period of 1
if gracePeriod < 1 {
gracePeriod = 1
}
return gracePeriod, status.gracePeriod != 0 && status.gracePeriod != gracePeriod
}
ApiServer 的行为
在上面分析 kubelet 处理的 pod 的退出时间时,我们看到 kubelet 首先使用了 pod 的DeletionGracePeriodSeconds,也就是 ApiServer 在删除 pod 时写入的值。在本节中,我们将分析 ApiServer 在删除 pod 时的行为。
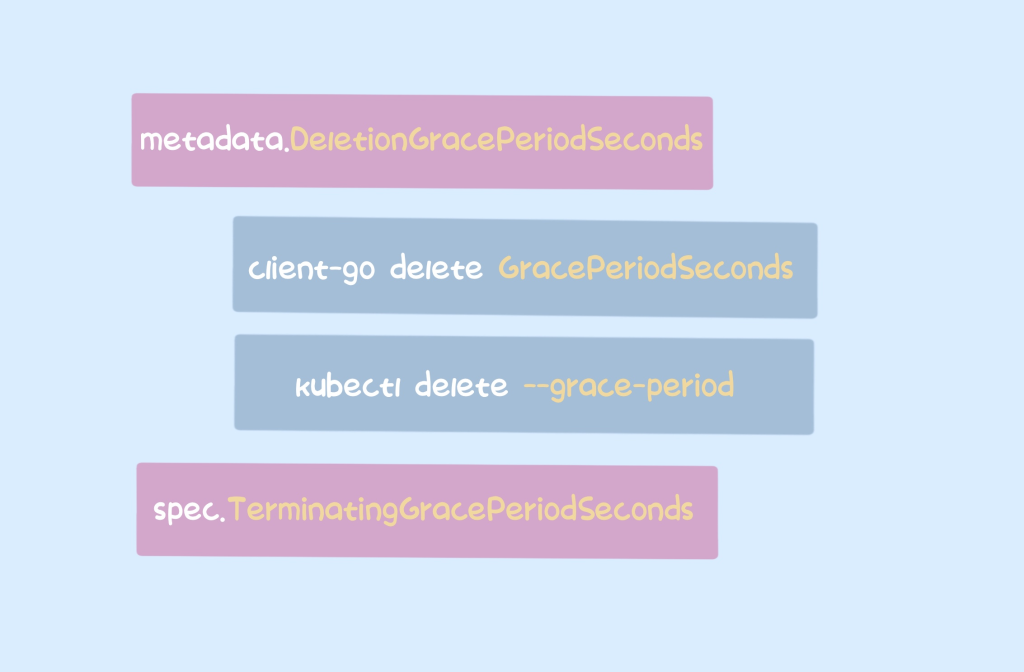
ApiServer中计算pod的GracePeriodSeconds的过程如下
options.GracePeriodSeconds如果不为空则设置为,否则设置为用户Spec.TerminationGracePeriodSeconds在规范中指定的(默认为 30s)。- 如果 pod 没有被调度或已经退出,即立即删除,则设置为 0。
where-options.GracePeriodSeconds是-grace-periodkubectl 删除 pod 时可以指定的参数,或者程序中调用 ApiServer 接口时可以指定的参数,比如DeleteOptions.GracePeriodSeconds在 client-go 中。
func (podStrategy) CheckGracefulDelete(ctx context.Context, obj runtime.Object, options *metav1.DeleteOptions) bool {
if options == nil {
return false
}
pod := obj.(*api.Pod)
period := int64(0)
// user has specified a value
if options.GracePeriodSeconds != nil {
period = *options.GracePeriodSeconds
} else {
// use the default value if set, or deletes the pod immediately (0)
if pod.Spec.TerminationGracePeriodSeconds != nil {
period = *pod.Spec.TerminationGracePeriodSeconds
}
}
// if the pod is not scheduled, delete immediately
if len(pod.Spec.NodeName) == 0 {
period = 0
}
// if the pod is already terminated, delete immediately
if pod.Status.Phase == api.PodFailed || pod.Status.Phase == api.PodSucceeded {
period = 0
}
if period < 0 {
period = 1
}
// ensure the options and the pod are in sync
options.GracePeriodSeconds = &period
return true
}
kubelet 驱逐 pod
此外,当 pod 被 kubelet 驱逐时,pod 的优雅退出时间会被覆盖。

func (m *managerImpl) synchronize(diskInfoProvider DiskInfoProvider, podFunc ActivePodsFunc) []*v1.Pod {
...
// we kill at most a single pod during each eviction interval
for i := range activePods {
pod := activePods[i]
gracePeriodOverride := int64(0)
if !isHardEvictionThreshold(thresholdToReclaim) {
gracePeriodOverride = m.config.MaxPodGracePeriodSeconds
}
message, annotations := evictionMessage(resourceToReclaim, pod, statsFunc)
if m.evictPod(pod, gracePeriodOverride, message, annotations) {
metrics.Evictions.WithLabelValues(string(thresholdToReclaim.Signal)).Inc()
return []*v1.Pod{pod}
}
}
...
}
覆盖值是EvictionMaxPodGracePeriod并且仅对软驱逐有效,这是 kubelet 的驱逐相关配置参数。
// Map of signal names to quantities that defines hard eviction thresholds. For example: {"memory.available": "300Mi"}.
EvictionHard map[string]string
// Map of signal names to quantities that defines soft eviction thresholds. For example: {"memory.available": "300Mi"}.
EvictionSoft map[string]string
// Map of signal names to quantities that defines grace periods for each soft eviction signal. For example: {"memory.available": "30s"}.
EvictionSoftGracePeriod map[string]string
// Duration for which the kubelet has to wait before transitioning out of an eviction pressure condition.
EvictionPressureTransitionPeriod metav1.Duration
// Maximum allowed grace period (in seconds) to use when terminating pods in response to a soft eviction threshold being met.
EvictionMaxPodGracePeriod int32
从 kubelet 中驱逐 pod 的函数在启动时注入以下函数。
func killPodNow(podWorkers PodWorkers, recorder record.EventRecorder) eviction.KillPodFunc {
return func(pod *v1.Pod, isEvicted bool, gracePeriodOverride *int64, statusFn func(*v1.PodStatus)) error {
// determine the grace period to use when killing the pod
gracePeriod := int64(0)
if gracePeriodOverride != nil {
gracePeriod = *gracePeriodOverride
} else if pod.Spec.TerminationGracePeriodSeconds != nil {
gracePeriod = *pod.Spec.TerminationGracePeriodSeconds
}
// we timeout and return an error if we don't get a callback within a reasonable time.
// the default timeout is relative to the grace period (we settle on 10s to wait for kubelet->runtime traffic to complete in sigkill)
timeout := int64(gracePeriod + (gracePeriod / 2))
minTimeout := int64(10)
if timeout < minTimeout {
timeout = minTimeout
}
timeoutDuration := time.Duration(timeout) * time.Second
// open a channel we block against until we get a result
ch := make(chan struct{}, 1)
podWorkers.UpdatePod(UpdatePodOptions{
Pod: pod,
UpdateType: kubetypes.SyncPodKill,
KillPodOptions: &KillPodOptions{
CompletedCh: ch,
Evict: isEvicted,
PodStatusFunc: statusFn,
PodTerminationGracePeriodSecondsOverride: gracePeriodOverride,
},
})
// wait for either a response, or a timeout
select {
case <-ch:
return nil
case <-time.After(timeoutDuration):
recorder.Eventf(pod, v1.EventTypeWarning, events.ExceededGracePeriod, "Container runtime did not kill the pod within specified grace period.")
return fmt.Errorf("timeout waiting to kill pod")
}
}
}
killPodNowfunction 是 kubelet 在驱逐 pod 时调用的函数,是软驱逐时设置gracePeriodOverride的参数,不设置时gracePeriod仍然取 的值pod. TerminationGracePeriodSeconds。然后,此函数调用podWorkers.UpdatePod,传入适当的参数,设置与 关联的超时gracePeriod,并等待它返回。
概括
Pod 的优雅退出是通过 preStop 实现的。本文简要分析了影响 Pod 正常退出和被驱逐的退出时间的因素,以及各个参数之间的交互方式。了解了这些细节后,我们对 Pod 退出过程有了更全面的了解。
