零停机迁移到Kubernetes:为什么 & 怎么做[转]
我们在Manifold始终致力于所做的一切都能得到充分利用。出于这个原因,我们不断地考量做过的一些事情,看看它是否仍然满足我们的标准。就在前阵子,我们决定深入研究一下我们的基础设施设定。
在这篇文章里,我们将一起来看看我们迁移到Kubernetes的原因以及我们自问自答的一些问题。随后,我们将一起来看看我们为了迁移到Kubernetes不得不做出的一些妥协,以及为什么需要做出这些妥协。我们也会一起来看看我们是如何配置集群来实现目标。
如果没坏的话,别去修
我们刚到Manifold时,做了我们熟知的一些工作。我们使用Terraform在AWS EC2上部署容器并且通过ELB对外提供服务。我们发现自己的处境是可以花费更多时间来构建一个更成熟的平台。刚开始实施的方案是非常简单的,但是我们开始看到一些痛点:
在过去一年里,Kubernetes变得更加受欢迎。凭借团队以往的经验,我们坚信这项新技术的未来。出于这个原因,我们创建了我们的第一个Kubernetes集成。我们也开始思考怎样集成可以使得Kubernetes变得更易于访问。这也正是萌生出构建Heighliner的想法的地方。
这也引领着我们坚持另外一个生存原则:自给自足。通过用Manifold来构建Manifold,我们也得以确切知道我们用户的需求。
选择一个集群
我们问自己的第一个问题是:“我们要在哪里运行这个集群?”。 AWS目前还没有提供Kubernetes的解决方案,但是Azure和Google云平台都有。我们是否需要留在AWS然后管理自己的集群,还是需要将所有内容迁移到其他云厂商?
我们想要解答的一些关键问题是:
高可用(HA)和kops
如果我们可以在AWS上轻松地创建和管理一个集群的话,那么自然没有太多必要去更换厂商。我们用kops做的初步测试看上去很有希望,而且我们决定进一步推进。是时候去配置一套高可用的集群了。
为了理解HA对于Kubernetes的意义,我们首先得明白它的通用含义。
一个高可用解决方案的核心基石是一个冗余的,可靠的存储层。高可用的第一原则就是保护数据。无论发生什么意外,无论是怎样的故障,如果你有数据,你就可以重建。如果你丢失了数据,那就完蛋了。

高可用配置下的Kubernetes组件
在一个Kubernetes集群里,这个存储层是etcd,并且运行在master实例上。etcd是一个分布式的键值对存储,它遵循Raft共识算法来实现仲裁。实现仲裁意味着有一组服务器赞成一组值。为了达成这一共识,它需要lower(n/2)+1的群体投赞成票。因此,我们往往需要的实例数量是至少3个。
下面,我们来看几个可能的故障情况。
容忍实例故障
第一个场景是一起来看看单个实例终止时会发生什么。我们能从中恢复吗?
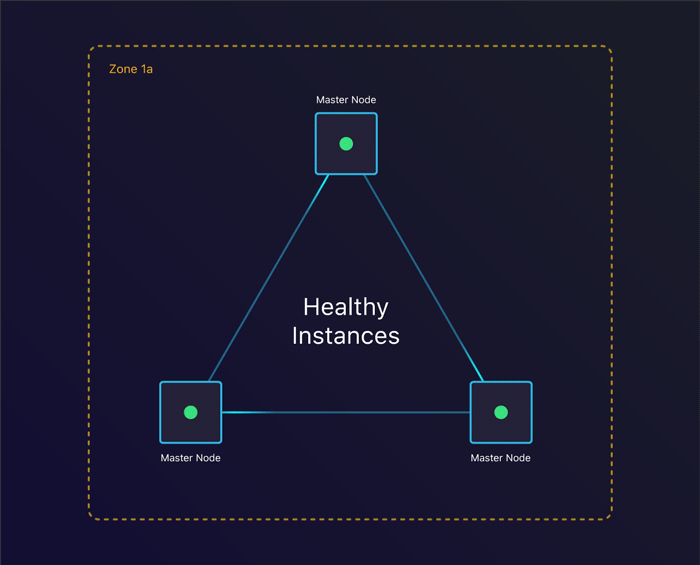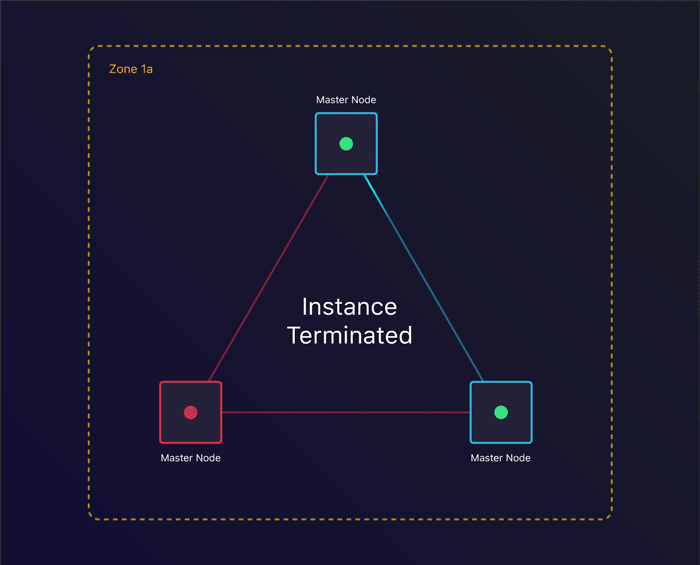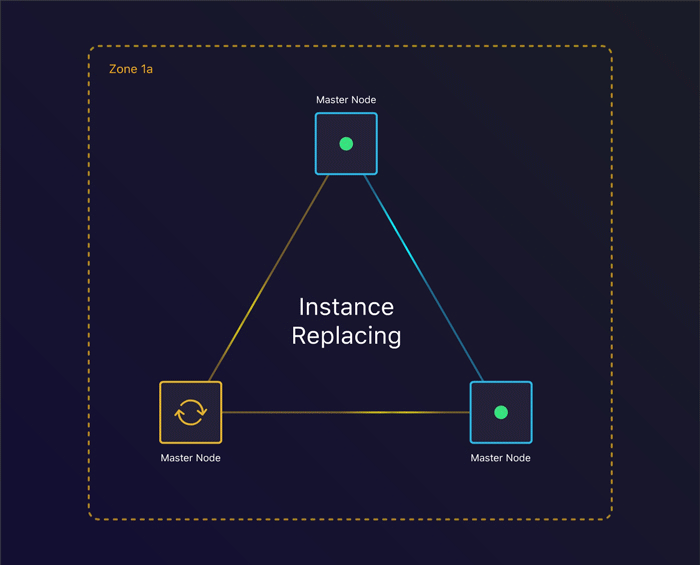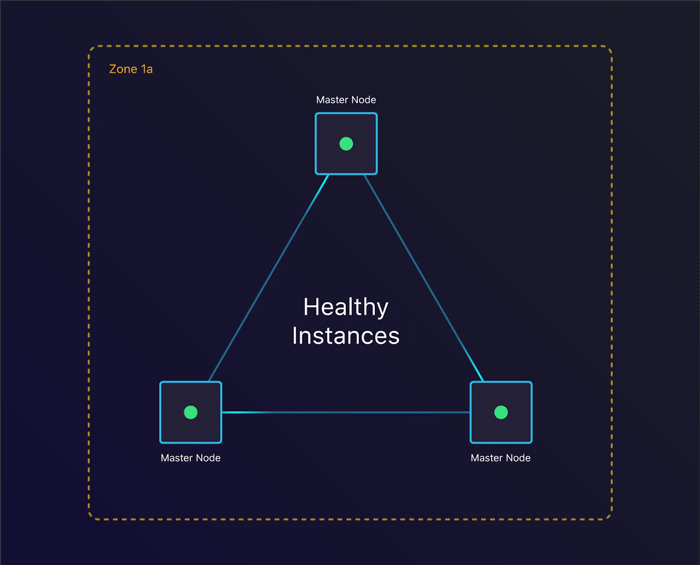
容忍实例故障
通过指定我们期望的节点数量,kops会为每个实例组创建一个自动扩容组。它将确保在一个实例终止时,会创建出来一个新的实例替代它。这使得我们在失去一个实例时仍然能够保持整个集群的一致。
容忍区域(zone)故障
配置实例级别的故障处理使得我们可以容忍单台机器层面的故障。但是如果整个数据中心出了问题,比如机房断电了,会发生什么情况呢?这时候就该地区(Region)和可用区域(AZ)的设定发挥作用了。
让我们一起回头看下我们的共识公式:lower(n/2)+1即至少3个实例。我们不妨把这个翻译成区域,结果就是lower(n/2)+1的区域即至少3个可用区域。
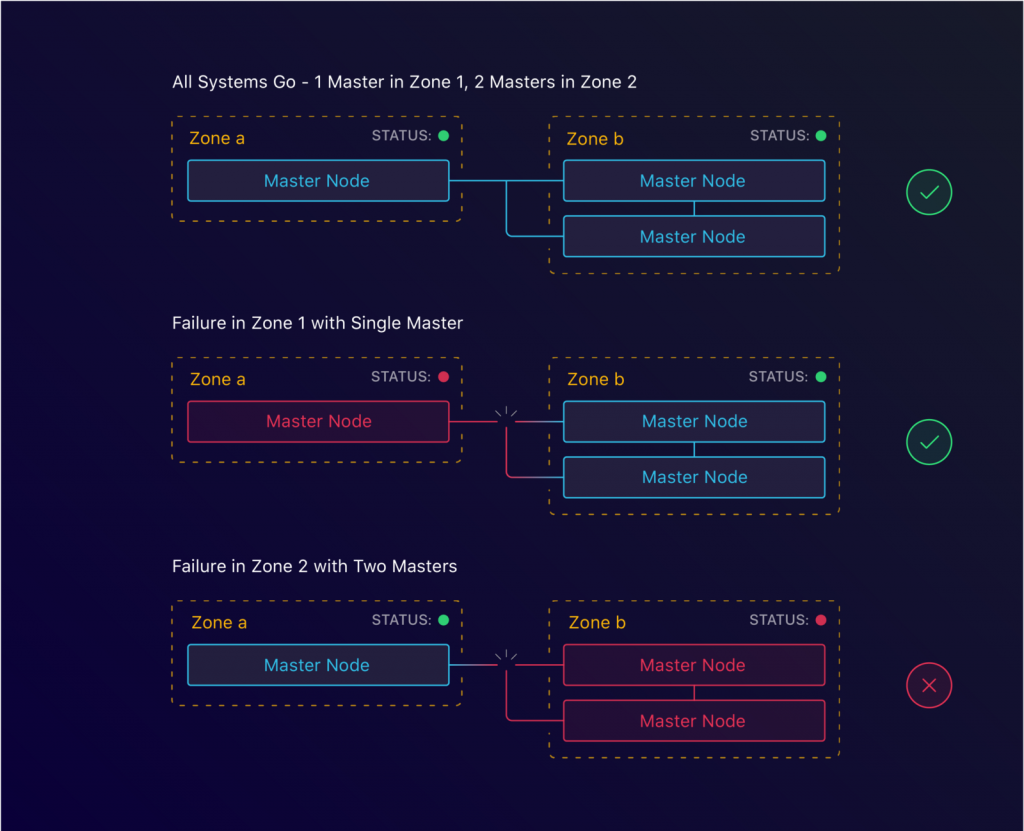
横跨两个区域的3个master节点
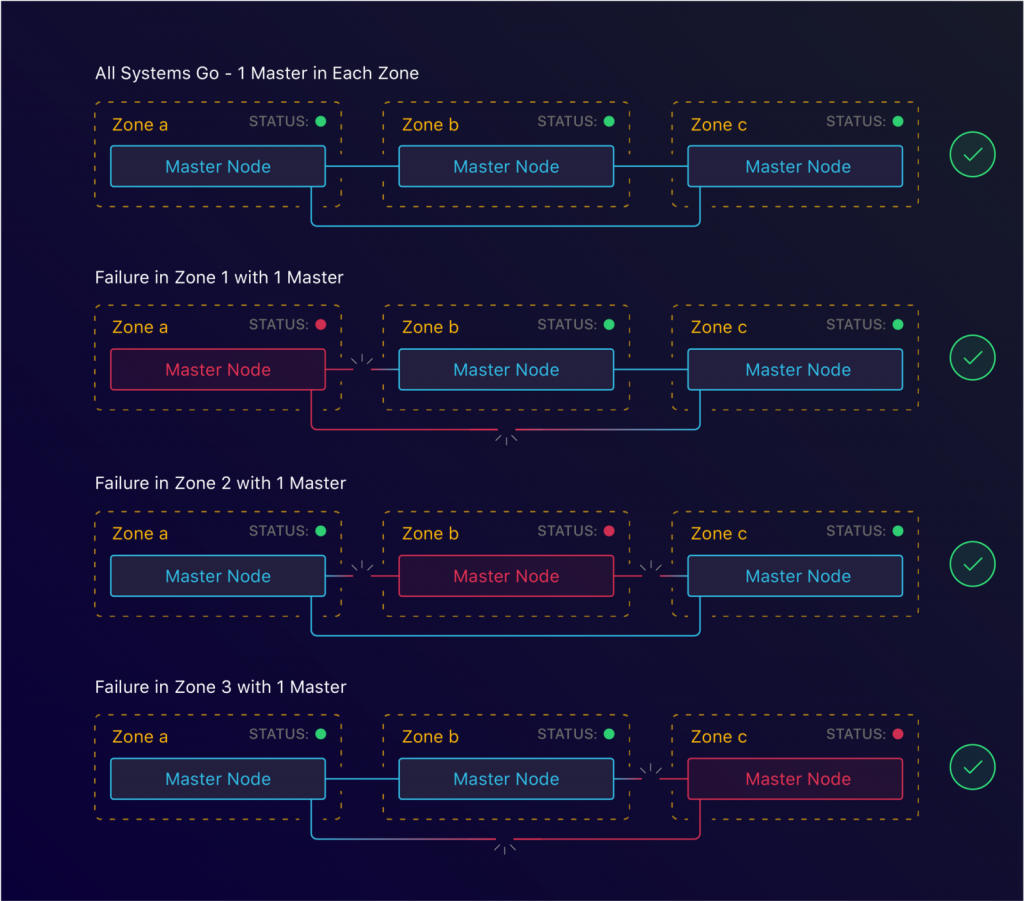
横跨三个区域的3个master节点
借助kops,这同样很简单就能办到。通过指定我们master和从节点所要运行的区域,我们可以在区域层面配置HA。然而,这是我们遇到的第一个阻力。无论是出于什么原因,总之我们刚开始在Manifold的时候,我们决定使用的地区是us-west-1。事实证明,该地区只有2个可用区域。这意味着我们必须找到另一种解决方案来容忍区域故障。
容忍地区故障 (而且不止如此)
主要目标是复制同步现有的基础设施。之前的基础设施采用的设定没有跨多个区域运行,因此新的配置也无需这样做。我们相信在Kubernetes Federation的帮助下,这将更容易建立起来。
对等内部网络
由于我们地区层面的限制,我们不得不寻找其他方式来容忍区域故障。一种选择是在一个单独的地区里创建我们的集群。
每个地区有它们自己单独的网络。这意味着我们无法直接在其他地区里使用这个地区的资源。针对这一点,我们研究了一下地区间的VPS对等。这将允许我们连到us-west-1地区然后访问RDS和KMS。

在us-west-1和us-west-2之间的地区间对等
这个方案也让我们失望了。事实证明,us-west-1地区不是最佳的地区选择。在我们调查这一点时,us-west-1还不支持地区间VPC对等。这意味着这个解决方案也无法使用。
决策和妥协
通过积累所有这些新的认知,是时候做出决定了。我们是选择仍然留在AWS还是迁移到其他厂商呢?
值得一提的是,迁移到其他厂商也会带来很多额外的开销。我们必须对外暴露我们的数据库,迁移我们的KMS并且重新加密我们所有的数据。
最后,我们决定坚持使用AWS并且执行容错节点故障的解决方案。随着Amazon EKS的发布以及即将推出的地区间对等,我们觉得这个开头已经足够出色了。
管理自己的集群可能会很花时间。迄今为止,我们已经看到了一些最小化的影响,但是我们肯定会把集群维护算在内。时间成本最高的应该是集群的更新。
从财务角度来看,我们也做出了妥协。是的,它比传统设备便宜,但是它比竞争对手提供的价格都要贵。Azure和GCP提供的主节点都是免费的,这相对可以降低一些成本。
kops的一些小贴士
对于我们而言,kops工作很出色。它提供了一组用户应该知道并且可以覆盖的默认值。我们要做的重要事情之一是启用etcd加密。这可以通过带上--encrypt-etcd-storage标志实现。
默认情况下,kops也不会启用RBAC。RBAC是一个很棒的限制集群里应用程序影响范畴的机制。我们强烈建议开启这一选项,并且为其设置合适的角色。
出于安全因素考虑,我们禁用了实例的SSH登陆。这可以确保即便我们使用私有的网络拓扑来运行也不会有人能够访问到这些实体。
配置集群
随着集群的启动和运行,现在是时候开始投产了。 下一步将是配置它,以便我们可以开始将应用程序部署到里面。
之前使用Terraform管理我们的服务意味着我们对于如何装配上线有相当大的控制权。我们通过Terraform配置管理我们的ELB,DNS,日志等。我们需要确保我们的Kubernetes配置上也能做到这些。
负载均衡
Kubernetes有Service和Ingress的概念。 通过Service,可以将Pod(通常由Deployment部署)进行分组,并把它们暴露在相同的端点下。该端点可以是内部的也可以是外部的。将一个service配置为负载均衡器时,Kubernetes将生成一个ELB。这个ELB随后将链接到配置好的service。

这很棒,但是这样做也限制了可以拥有的ELB数量。通过使用Ingress,我们可以创建一个单个的ELB然后在集群内路由流量。社区里有几个可选的Ingress,但是我们使用默认的Nginx Ingress。
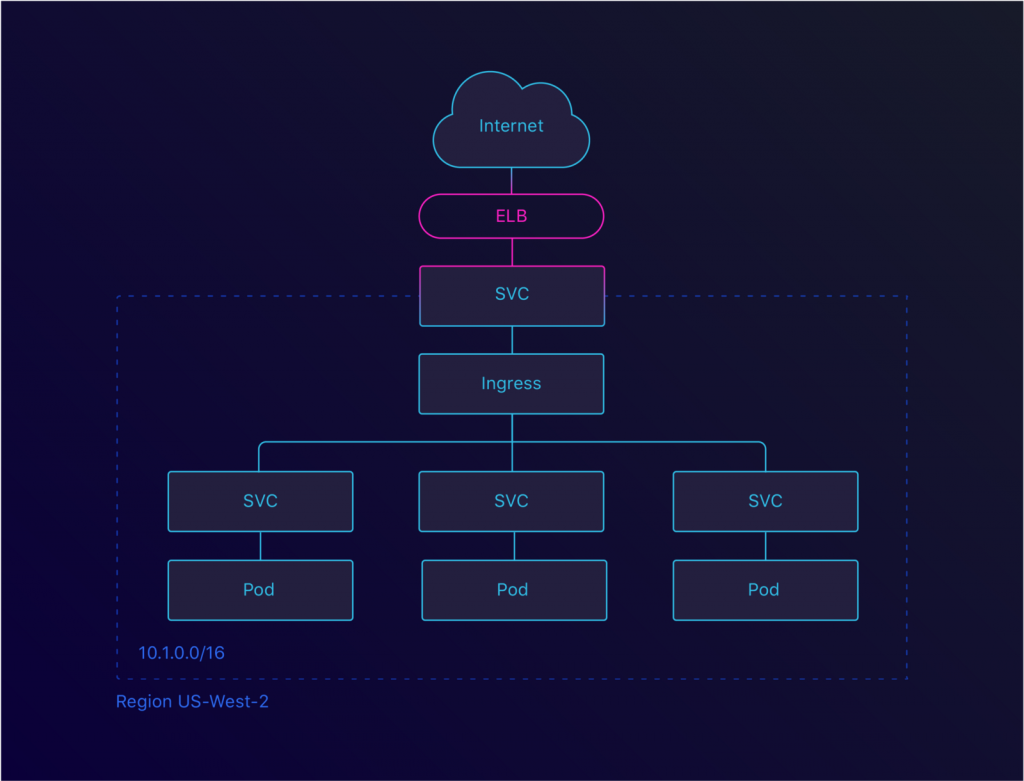
External DNS项目。这是一个很好的保持配置好的域名贴近应用的方式。
为了对外暴露我们的服务,还需要考虑的最后一步便是确保我们可以在SSL下提供流量。事实证明这件事很容易办到,而且已经有现成可用的解决方案。我们选择了cert-manager,它可以和我们的Nginx Ingress集成。
服务配置
服务配置对我们来说是轻而易举。我们已经开始在和Terraform集成后的Manifold之上构建Manifold自己。正因为如此,我们需要的所有证书都已经配置好了。
我们精心设计了Kubernetes集成和Terraform的集成。我们保持底层的语义相同,这意味着迁移证书不再是件难事。
我们还添加了自定义secret类型的选项。这使得我们能够配置Docker认证的密码。在从私有镜像中心里拉取Docker镜像时,用户需要知道这个密码。
监测
运行分布式系统最重要的事情之一就是需要知道内部发生了什么。为此,用户需要配置集中式的日志和监控指标。我们在之前的传统平台上有这个功能,因此在我们的新平台中肯定也需要有这个功能。
关于日志,我们扩展了我们的dogfooding并且配置了LogDNA集成来收集日志。 LogDNA本身提供了一个DaemonSet配置。这使得用户可以将集群中的日志发送到他们的平台。
关于监控指标,我们依赖Datadog,迄今为止我们和它合作的很好。同LogDNA一样,Datadog也提供了一个DaemonSet配置。 他们甚至还有一篇很棒的关于如何配置的博客文章!
迁移
在配置好集群然后部署了我们的应用程序之后,是时候该迁移了。为了确保零停机时间,我们必须分几个阶段来完成。
第一个阶段是在单独的域上运行集群。通过连通两个系统,我们可以在不打断任何人工作的情况下进行测试。这帮助我们找到并解决了一些早期遇到的问题。
在接下来的阶段,我们会将一些流量路由到Kubernetes集群。 为此,我们配置了一个轮询。这是一个查看接入真实流量后的用户集群行为的好办法。大约一周后,我们已经有足够的信心进入到下一阶段。
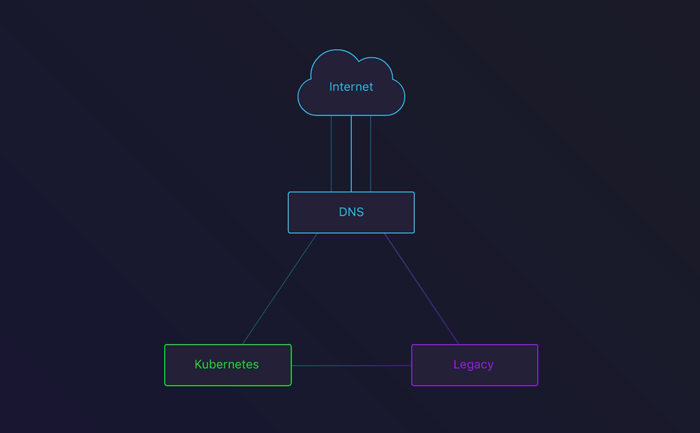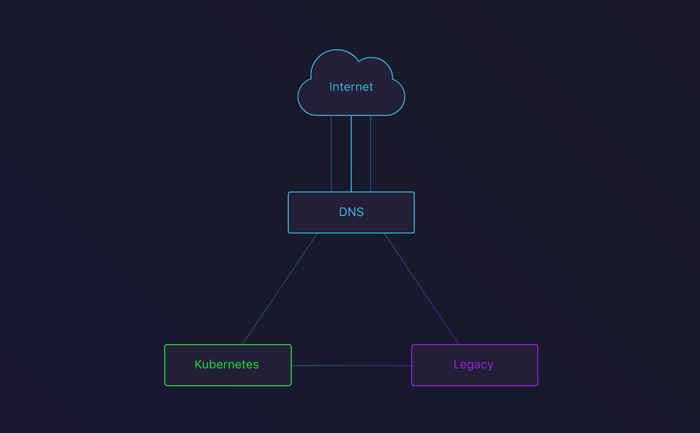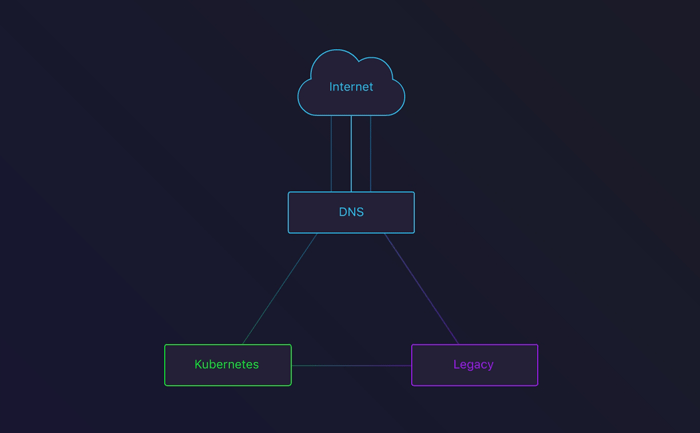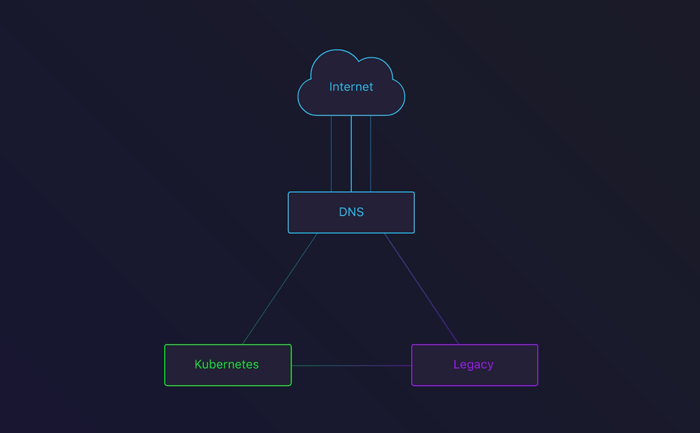
在旧基础设施和Kubernetes集群之间配置的DNS round-robin
第三个阶段涉及的便是删除旧的DNS记录。在删除对应的Terraform配置后,我们所有的流量都将流向Kubernetes!
由于DNS缓存的原因,我们决定让这些旧版本继续运行几天。这样一来,缓存了DNS记录的用户就不会遇到错误。这也让我们有能力在出现问题的情况下回滚。
总结
现在我们已经完成了迁移,我们可以回过头来反思一些东西。我们的团队——和公司——都说这次迁移很成功。我们将部署时间从大约15分钟缩短到大约1.5分钟,并以此降低了运营成本。
我们还没完成我们的持续交付流水线,这方面我们仍然在努力。我们已经开始了Heighliner的开发工作,它将以能够帮到我们放到第一位,不过也希望能够帮到其他人。
我们遇到了一个重大挫折:没有3个可用区域供我们使用。这阻碍我们跨区域运行的高可用性。决定启动和运行也是一次妥协,我们将尽快完全解决这一问题。
哦,还有一件事。太多的YAML了。这也是Heighliner将能够帮到我们的地方。