kubernetes 集群无法正常访问pod服务端口,内部访问正常
问题现象
公司内网kubernetes集群中之前部署了一个新项目,最近开发反应访问业务域名时而会出现无法访问或连接超时的情况。 通过ping 、telnet 排除了网络问题, 登录到容器内部查看应用日志正常、检查业务端口正常、 curl localhost:6674通过应用返回状态码可以确认业务正常。
定位过程
1、网络
出现问题时,kubectl exec进入容器,发现ping 其他容器正常,说明容器的网络是正常的。 curl 本机也是正常
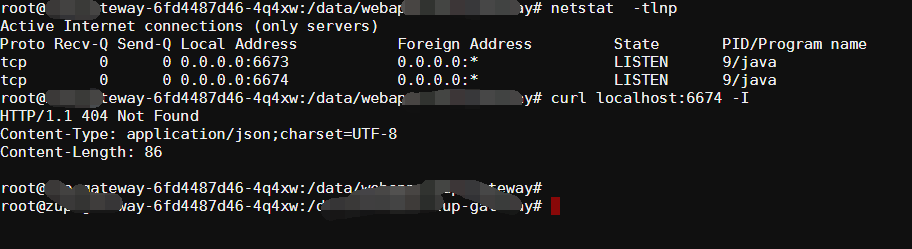
2、进程
在服务端上tcpdump抓包,可以看到客户端发过来的syn报文,但是服务端并没有应答,导致syn报文一直重传。从抓包看到只有收到syn没有应答syn+ack,就可以肯定跟用户态的业务进程无关了:tcp三次握手完全是内核完成的,只有3次握手结束,内核才会给用户态进程上报事件;用户态最多就是不响应该事件,但不会造成不应答syn+ack。
3、内核
只有这种可能了。linux内核调试起来比较麻烦,不过可以通过proc来看一些统计信息。
[root@f-k8s-node2-192-168-1-18 ~]# cat /proc/net/netstat TcpExt: SyncookiesSent SyncookiesRecv SyncookiesFailed EmbryonicRsts PruneCalled RcvPruned OfoPruned OutOfWindowIcmps LockDroppedIcmps ArpFilter TW TWRecycled TWKilled PAWSPassive PAWSActive PAWSEstab DelayedACKs DelayedACKLocked DelayedACKLost ListenOverflows ListenDrops TCPPrequeued TCPDirectCopyFromBacklog TCPDirectCopyFromPrequeue TCPPrequeueDropped TCPHPHits TCPHPHitsToUser TCPPureAcks TCPHPAcks TCPRenoRecovery TCPSackRecovery TCPSACKReneging TCPFACKReorder TCPSACKReorder TCPRenoReorder TCPTSReorder TCPFullUndo TCPPartialUndo TCPDSACKUndo TCPLossUndo TCPLostRetransmit TCPRenoFailures TCPSackFailures TCPLossFailures TCPFastRetrans TCPForwardRetrans TCPSlowStartRetrans TCPTimeouts TCPLossProbes TCPLossProbeRecovery TCPRenoRecoveryFail TCPSackRecoveryFail TCPSchedulerFailed TCPRcvCollapsed TCPDSACKOldSent TCPDSACKOfoSent TCPDSACKRecv TCPDSACKOfoRecv TCPAbortOnData TCPAbortOnClose TCPAbortOnMemory TCPAbortOnTimeout TCPAbortOnLinger TCPAbortFailed TCPMemoryPressures TCPSACKDiscard TCPDSACKIgnoredOld TCPDSACKIgnoredNoUndo TCPSpuriousRTOs TCPMD5NotFound TCPMD5Unexpected TCPSackShifted TCPSackMerged TCPSackShiftFallback TCPBacklogDrop TCPMinTTLDrop TCPDeferAcceptDrop IPReversePathFilter TCPTimeWaitOverflow TCPReqQFullDoCookies TCPReqQFullDrop TCPRetransFail TCPRcvCoalesce TCPOFOQueue TCPOFODrop TCPOFOMerge TCPChallengeACK TCPSYNChallenge TCPFastOpenActive TCPFastOpenActiveFail TCPFastOpenPassive TCPFastOpenPassiveFail TCPFastOpenListenOverflow TCPFastOpenCookieReqd TCPSpuriousRtxHostQueues BusyPollRxPackets TCPAutoCorking TCPFromZeroWindowAdv TCPToZeroWindowAdv TCPWantZeroWindowAdv TCPSynRetrans TCPOrigDataSent TCPHystartTrainDetect TCPHystartTrainCwnd TCPHystartDelayDetect TCPHystartDelayCwnd TCPACKSkippedSynRecv TCPACKSkippedPAWS TCPACKSkippedSeq TCPACKSkippedFinWait2 TCPACKSkippedTimeWait TCPACKSkippedChallenge TcpExt: 0 0 1567 1 0 0 0 54 0 0 3799 0 2080938 0 0 0 939485 3344 2600 0 0 28 1950 9964 0 24895822 2 17098305 36033243 0 42 0 0 3 0 2 0 3 37 5 0 0 0 0 128 0 0 79 1578 509 0 0 0 0 2600 0 747 0 502636 1274 0 22 0 0 0 0 0 419 0 0 0 9 11 116 0 0 0 0 0 0 0 0 1529462 7826 0 0 5 0 0 0 0 0 0 0 61 0 8334464 468 468 1570 57 171336918 369 6743 0 0 0 0 0 0 0 0 IpExt: InNoRoutes InTruncatedPkts InMcastPkts OutMcastPkts InBcastPkts OutBcastPkts InOctets OutOctets InMcastOctets OutMcastOctets InBcastOctets OutBcastOctets InCsumErrors InNoECTPkts InECT1Pkts InECT0Pkts InCEPkts IpExt: 0 0 44457 0 1600678 0 1057270745794 1798965484220 1422648 0 184448881 0 0 2993895134 0 4131 0
https://github.com/silenceshell/netproc
发现PAWSPassive的计数跟ListenDrops是一致的?
两次netstat的信息:
PAWSPassive 3565 3858
ListenDrops 3565 3858
随后使用Wireshark抓包后发现客户端发出SYN包到服务端,而此时服务端已经收到了syn包但没有返回应答报文(synack)。
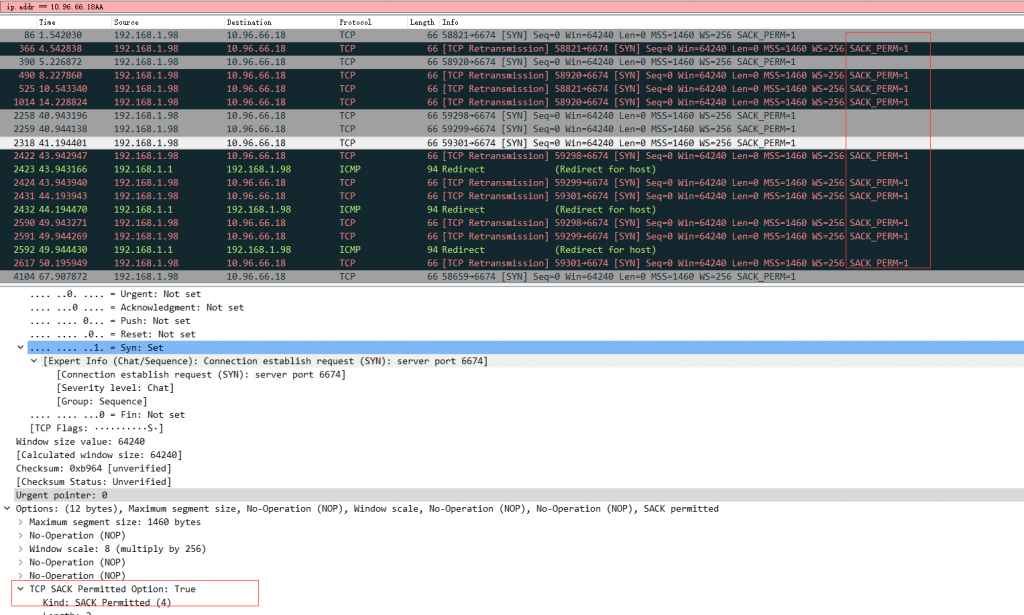
如上图,为了方便在info列中查看SACK信息。 RFC6675中对于SACK下dup ACK的定义如下
For the purposes of this specification, we define a “duplicate acknowledgment” as a segment that arrives carrying a SACK block that identifies previously unacknowledged and un-SACKed octets between HighACK and HighData. Note that an ACK which carries new SACK data is counted as a duplicate acknowledgment under this definition even if it carries new data, changes the advertised window, or moves the cumulative acknowledgment point, which is different from the definition of duplicate acknowledgment in [RFC5681].
处理过程
请求基本就是发出syn后server没回包。看到这个就有点怀疑server端是不是开启了tcp_tw_recycle和tcp_timestamps 。 此时我们需要使用kubectl get endpoints 和kubectl get pod -o wide 查看对应的pod被调度到那台node节点, 登录node节点查看内核参数。
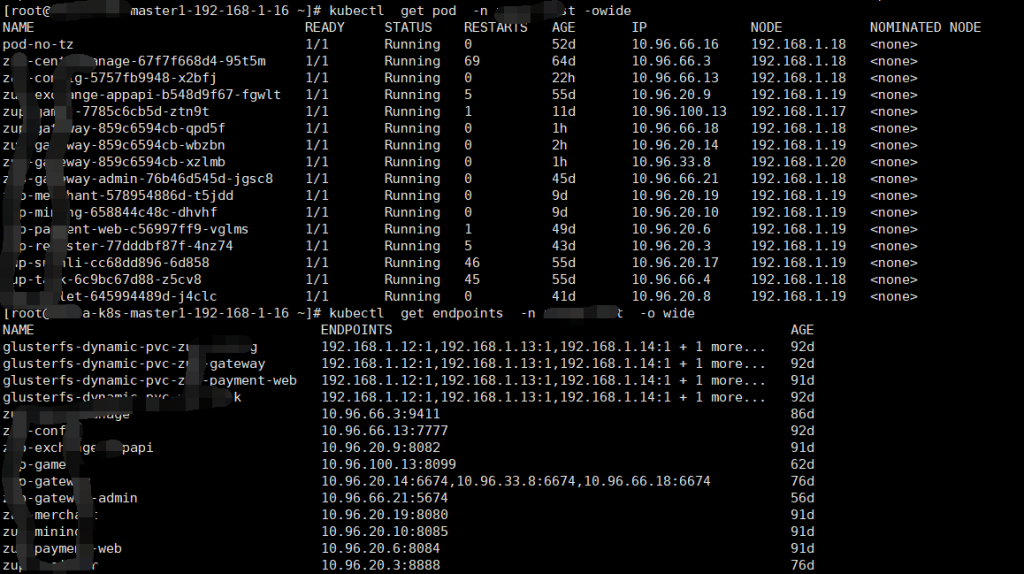
vim /etc/sysctl.conf #查看内核参数, 可以看到net.ipv4.tcp_tw_recycle = 1 被设置为了1。
关于tcp_tw_recycle参数 Enable fast recycling of TIME-WAIT sockets. Enabling this option is not recommended since this causes problems when working with NAT (Network Address Translation). 启用TIME-WAIT状态sockets的快速回收,这个选项不推荐启用。在NAT(Network Address Translation)网络下,会导致大量的TCP连接建立错误。
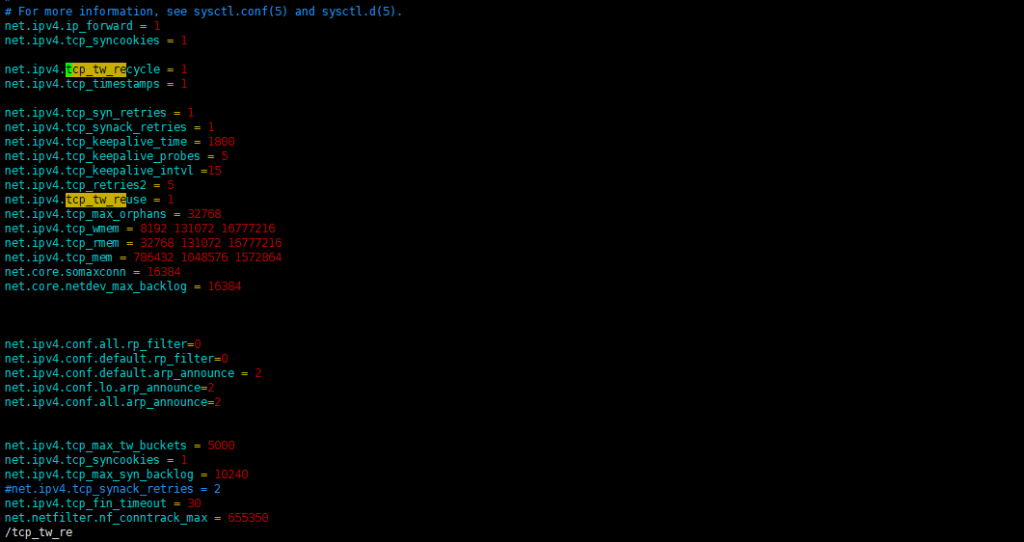
为什么开启net.ipv4.tcp_tw_recycle?
开启net.ipv4.tcp_tw_recycle的目的,就是希望能够加快TIME_WAIT状态的回收,当然这个选项的生效也依赖于net.ipv4.tcp_timestamps的开启(缺省就是开启的)。
当开启了tcp_tw_recycle选项后,当连接进入TIME_WAIT状态后,会记录对应远端主机最后到达分节的时间戳。如果同样的主机有新的分节到达,且时间戳小于之前记录的时间戳,即视为无效,相应的数据包会被丢弃
原因分析
若远端服务器的内核参数 net.ipv4.tcp_tw_recycle 和 net.ipv4.tcp_timestamps 的值都为 1,则远端服务器会检查每一个报文中的时间戳(Timestamp),若 Timestamp 不是递增的关系,不会响应这个报文。配置 NAT 后,远端服务器看到来自不同的客户端的源 IP 相同,但 NAT 前每一台客户端的时间可能会有偏差,报文中的 Timestamp 就不是递增的情况。
解决方法
只要将net.ipv4.tcp_tw_recycle 、net.ipv4.tcp_timestamps 两个参数恢复为默认值0即可。