Kubernetes Pod删除操作源码分析
例如,现在我有一个更新策略为 的应用程序Recreate,然后执行删除命令如下。
☸ ➜ kubectl get pods NAME READY STATUS RESTARTS AGE minio-875749785-sv5ns 1/1 Running 1 (2m52s ago) 42h ☸ ➜ kubectl delete pod minio-875749785-sv5ns pod "minio-875749785-sv5ns" deleted
在删除之前观察另一个终端上的应用程序状态。
☸ ➜ kubectl get pods -w NAME READY STATUS RESTARTS AGE minio-875749785-sv5ns 1/1 Running 1 (2m46s ago) 42h minio-875749785-sv5ns 1/1 Terminating 1 (2m57s ago) 42h minio-875749785-h2j2b 0/1 Pending 0 0s minio-875749785-h2j2b 0/1 Pending 0 0s minio-875749785-h2j2b 0/1 ContainerCreating 0 0s minio-875749785-sv5ns 0/1 Terminating 1 (2m59s ago) 42h minio-875749785-sv5ns 0/1 Terminating 1 (2m59s ago) 42h minio-875749785-sv5ns 0/1 Terminating 1 (2m59s ago) 42h minio-875749785-h2j2b 0/1 Running 0 17s minio-875749785-h2j2b 1/1 Running 0 30s
从上面的过程可以看出,我们执行kubectl delete命令后Pod就变成了Terminating,然后就消失了。接下来,我们将从代码的角度来描述删除 Pod 的整个过程。
这里我们以 Kubernetes 版本
v1.22.8为例。其他版本不保证完全相同,但总体思路是一样的。
删除状态
我们可以根据我们在 kubectl 操作后看到的内容来跟踪状态,上面的格式化是使用代码https://github.com/kubernetes/kubernetes/blob/v1.22.8/pkg/printers/internalversion/printers.go#L88-L102。这如下所示。
// TODO: handle errors from Handler
func AddHandlers(h printers.PrintHandler) {
podColumnDefinitions := []metav1.TableColumnDefinition{
{Name: "Name", Type: "string", Format: "name", Description: metav1.ObjectMeta{}.SwaggerDoc()["name"]},
{Name: "Ready", Type: "string", Description: "The aggregate readiness state of this pod for accepting traffic."},
{Name: "Status", Type: "string", Description: "The aggregate status of the containers in this pod."},
{Name: "Restarts", Type: "string", Description: "The number of times the containers in this pod have been restarted and when the last container in this pod has restarted."},
{Name: "Age", Type: "string", Description: metav1.ObjectMeta{}.SwaggerDoc()["creationTimestamp"]},
{Name: "IP", Type: "string", Priority: 1, Description: apiv1.PodStatus{}.SwaggerDoc()["podIP"]},
{Name: "Node", Type: "string", Priority: 1, Description: apiv1.PodSpec{}.SwaggerDoc()["nodeName"]},
{Name: "Nominated Node", Type: "string", Priority: 1, Description: apiv1.PodStatus{}.SwaggerDoc()["nominatedNodeName"]},
{Name: "Readiness Gates", Type: "string", Priority: 1, Description: apiv1.PodSpec{}.SwaggerDoc()["readinessGates"]},
}
h.TableHandler(podColumnDefinitions, printPodList)
h.TableHandler(podColumnDefinitions, printPod)
使用函数获取 Pod 的输出printPod,代码位于:https://github.com/kubernetes/kubernetes/blob/v1.22.8/pkg/printers/internalversion/printers.go#L756-L840 ,其中有一段代码引用了该Terminating值,如果pod.DeletionTimestamp ! = nil. 这如下所示。
if pod.DeletionTimestamp != nil && pod.Status.Reason == node.NodeUnreachablePodReason {
reason = "Unknown"
} else if pod.DeletionTimestamp != nil {
reason = "Terminating"
}
这意味着当执行删除操作时,DeletionTimestampPod 的属性被设置,并且此时Terminating显示状态。
执行删除操作时,会向 apiserver 发送 DELETE 请求。
I0408 11:25:33.002155 42938 round_trippers.go:435] curl -v -XDELETE -H "Content-Type: application/json" -H "User-Agent: kubectl/v1.22.7 (darwin/amd64) kubernetes/b56e432" -H "Accept: application/json" 'https://192.168.0.111:6443/api/v1/namespaces/default/pods/minio-875749785-sv5ns' I0408 11:25:33.037245 42938 round_trippers.go:454] DELETE https://192.168.0.111:6443/api/v1/namespaces/default/pods/minio-875749785-sv5ns 200 OK in 35 milliseconds
收到删除请求的处理器位于代码https://github.com/kubernetes/kubernetes/blob/v1.22.8/staging/src/k8s.io/apiserver/pkg/registry/generic/registry/store.go#L986。如下所示。
func (e *Store) Delete(ctx context.Context, name string, deleteValidation rest.ValidateObjectFunc, options *metav1.DeleteOptions) (runtime.Object, bool, error) {
key, err := e.KeyFunc(ctx, name)
if err != nil {
return nil, false, err
}
obj := e.NewFunc()
qualifiedResource := e.qualifiedResourceFromContext(ctx)
if err = e.Storage.Get(ctx, key, storage.GetOptions{}, obj); err != nil {
return nil, false, storeerr.InterpretDeleteError(err, qualifiedResource, name)
}
// support older consumers of delete by treating "nil" as delete immediately
if options == nil {
options = metav1.NewDeleteOptions(0)
}
var preconditions storage.Preconditions
if options.Preconditions != nil {
preconditions.UID = options.Preconditions.UID
preconditions.ResourceVersion = options.Preconditions.ResourceVersion
}
graceful, pendingGraceful, err := rest.BeforeDelete(e.DeleteStrategy, ctx, obj, options)
if err != nil {
return nil, false, err
}
// this means finalizers cannot be updated via DeleteOptions if a deletion is already pending
if pendingGraceful {
out, err := e.finalizeDelete(ctx, obj, false, options)
return out, false, err
}
// check if obj has pending finalizers
在BeforeDelete判断是否需要优雅删除的函数中,判断DeletionGracePeriodSeconds值是否为0,不为零则认为是优雅删除,apiserver不会立即从etcd中删除对象,否则直接删除。对于 Pods,默认DeletionGracePeriodSeconds是 30 秒,所以这里不是立即删除,而是DeletionTimestamp设置为当前时间,DeletionGracePeriodSeconds设置为默认值 30 秒。代码位于https://github.com/kubernetes/kubernetes/blob/v1.22.8/staging/src/k8s.io/apiserver/pkg/registry/rest/delete.go#L93-L159和这个函数中将设置 的值DeletionTimestamp。这如下所示。
// `CheckGracefulDelete` will be implemented by specific strategy
if !gracefulStrategy.CheckGracefulDelete(ctx, obj, options) {
return false, false, nil
}
if options.GracePeriodSeconds == nil {
return false, false, errors.NewInternalError(fmt.Errorf("options.GracePeriodSeconds should not be nil"))
}
now := metav1.NewTime(metav1.Now().Add(time.Second * time.Duration(*options.GracePeriodSeconds)))
objectMeta.SetDeletionTimestamp(&now)
objectMeta.SetDeletionGracePeriodSeconds(options.GracePeriodSeconds)
上面的代码验证了在执行删除操作的时候,apiserver会先将DeletionTimestampPod的属性设置为当前时间加上优雅删除优雅持续时间的时间点,设置完这个属性后,我们客户端格式化后看到的就是Terminating状态.
优雅的删除
由于 Pod 涉及到很多其他资源,比如沙箱容器、volume 卷等,删除后需要回收,而删除一个 Pod 归根结底就是删除对应的容器,这需要 Pod 的节点的 kubelet 来完成清理。kubelet 会首先一直关注我们的 Pod,当 Pod 的删除更新 Pod 的删除时间时,它自然会接收到该事件并进行相应的清理。
kubelet对Pods的处理主要在syncLoop函数中,调用事件相关的handler syncLoopIteration,代码位于https://github.com/kubernetes/kubernetes/blob/v1.22.8/pkg/kubelet/kubelet.go#L2040-L2079。这如下所示。
func (kl *Kubelet) syncLoopIteration(configCh <-chan kubetypes.PodUpdate, handler SyncHandler,
syncCh <-chan time.Time, housekeepingCh <-chan time.Time, plegCh <-chan *pleg.PodLifecycleEvent) bool {
select {
case u, open := <-configCh:
// Update from a config source; dispatch it to the right handler
// callback.
if !open {
klog.ErrorS(nil, "Update channel is closed, exiting the sync loop")
return false
}
switch u.Op {
case kubetypes.ADD:
klog.V(2).InfoS("SyncLoop ADD", "source", u.Source, "pods", format.Pods(u.Pods))
// After restarting, kubelet will get all existing pods through
// ADD as if they are new pods. These pods will then go through the
// admission process and *may* be rejected. This can be resolved
// once we have checkpointing.
handler.HandlePodAdditions(u.Pods)
case kubetypes.UPDATE:
klog.V(2).InfoS("SyncLoop UPDATE", "source", u.Source, "pods", format.Pods(u.Pods))
handler.HandlePodUpdates(u.Pods)
case kubetypes.REMOVE:
klog.V(2).InfoS("SyncLoop REMOVE", "source", u.Source, "pods", format.Pods(u.Pods))
handler.HandlePodRemoves(u.Pods)
case kubetypes.RECONCILE:
klog.V(4).InfoS("SyncLoop RECONCILE", "source", u.Source, "pods", format.Pods(u.Pods))
handler.HandlePodReconcile(u.Pods)
case kubetypes.DELETE:
klog.V(2).InfoS("SyncLoop DELETE", "source", u.Source, "pods", format.Pods(u.Pods))
// DELETE is treated as a UPDATE because of graceful deletion.
handler.HandlePodUpdates(u.Pods)
case kubetypes.SET:
// TODO: Do we want to support this?
klog.ErrorS(nil, "Kubelet does not support snapshot update")
default:
klog.ErrorS(nil, "Invalid operation type received", "operation", u.Op)
}
kl.sourcesReady.AddSource(u.Source)
执行删除操作时,apiserver 会首先更新DeletionTimestampPod 中的属性。这个改动是对kubelet的更新操作,所以会对应kubetypes.UPDATE操作,调用HandlePodUpdates函数来更新。
// HandlePodUpdates is the callback in the SyncHandler interface for pods
// being updated from a config source.
func (kl *Kubelet) HandlePodUpdates(pods []*v1.Pod) {
start := kl.clock.Now()
for _, pod := range pods {
kl.podManager.UpdatePod(pod)
if kubetypes.IsMirrorPod(pod) {
kl.handleMirrorPod(pod, start)
continue
}
mirrorPod, _ := kl.podManager.GetMirrorPodByPod(pod)
kl.dispatchWork(pod, kubetypes.SyncPodUpdate, mirrorPod, start)
}
}
HandlePodUpdates,dispatchWork调用将Pod删除分配给特定的worker进行处理,而podWorker是特定的执行者,即每次需要更新Pod时,都发送给podWorker。
// dispatchWork starts the asynchronous sync of the pod in a pod worker.
// If the pod has completed termination, dispatchWork will perform no action.
func (kl *Kubelet) dispatchWork(pod *v1.Pod, syncType kubetypes.SyncPodType, mirrorPod *v1.Pod, start time.Time) {
// Run the sync in an async worker.
kl.podWorkers.UpdatePod(UpdatePodOptions{
Pod: pod,
MirrorPod: mirrorPod,
UpdateType: syncType,
StartTime: start,
})
// Note the number of containers for new pods.
if syncType == kubetypes.SyncPodCreate {
metrics.ContainersPerPodCount.Observe(float64(len(pod.Spec.Containers)))
}
}
该dispatchWork方法调用UpdatePod删除Pod的函数,代码位于https://github.com/kubernetes/kubernetes/blob/v1.22.8/pkg/kubelet/pod_workers.go#L540-L765,其中Pod信息是通过一个通道,managePodLoop在一个goroutine中调用该函数来处理它,其中的syncTerminatingPod/syncPod方法执行删除操作。
最终killPod将调用该函数来执行 Pod 的删除。

该killPod函数调用容器运行时停止 Pod 中的容器,代码位于https://github.com/kubernetes/kubernetes/blob/v1.22.8/pkg/kubelet/kubelet_pods.go#L856-L868。
// killPod instructs the container runtime to kill the pod. This method requires that
// the pod status contains the result of the last syncPod, otherwise it may fail to
// terminate newly created containers and sandboxes.
func (kl *Kubelet) killPod(pod *v1.Pod, p kubecontainer.Pod, gracePeriodOverride *int64) error {
// Call the container runtime KillPod method which stops all known running containers of the pod
if err := kl.containerRuntime.KillPod(pod, p, gracePeriodOverride); err != nil {
return err
}
if err := kl.containerManager.UpdateQOSCgroups(); err != nil {
klog.V(2).InfoS("Failed to update QoS cgroups while killing pod", "err", err)
}
return nil
}
容器运行时的 KillPod 方法位于https://github.com/kubernetes/kubernetes/blob/v1.22.8/pkg/kubelet/kuberuntime/kuberuntime_manager.go#L969-L998。如下图所示。
// KillPod kills all the containers of a pod. Pod may be nil, running pod must not be.
// gracePeriodOverride if specified allows the caller to override the pod default grace period.
// only hard kill paths are allowed to specify a gracePeriodOverride in the kubelet in order to not corrupt user data.
// it is useful when doing SIGKILL for hard eviction scenarios, or max grace period during soft eviction scenarios.
func (m *kubeGenericRuntimeManager) KillPod(pod *v1.Pod, runningPod kubecontainer.Pod, gracePeriodOverride *int64) error {
err := m.killPodWithSyncResult(pod, runningPod, gracePeriodOverride)
return err.Error()
}
// killPodWithSyncResult kills a runningPod and returns SyncResult.
// Note: The pod passed in could be *nil* when kubelet restarted.
func (m *kubeGenericRuntimeManager) killPodWithSyncResult(pod *v1.Pod, runningPod kubecontainer.Pod, gracePeriodOverride *int64) (result kubecontainer.PodSyncResult) {
killContainerResults := m.killContainersWithSyncResult(pod, runningPod, gracePeriodOverride)
for _, containerResult := range killContainerResults {
result.AddSyncResult(containerResult)
}
// stop sandbox, the sandbox will be removed in GarbageCollect
killSandboxResult := kubecontainer.NewSyncResult(kubecontainer.KillPodSandbox, runningPod.ID)
result.AddSyncResult(killSandboxResult)
// Stop all sandboxes belongs to same pod
for _, podSandbox := range runningPod.Sandboxes {
if err := m.runtimeService.StopPodSandbox(podSandbox.ID.ID); err != nil && !crierror.IsNotFound(err) {
killSandboxResult.Fail(kubecontainer.ErrKillPodSandbox, err.Error())
klog.ErrorS(nil, "Failed to stop sandbox", "podSandboxID", podSandbox.ID)
}
}
return
}
该killPodWithSyncResult方法首先调用该函数killContainersWithSyncResult杀死所有正在运行的容器,然后删除 Pod 的沙箱。
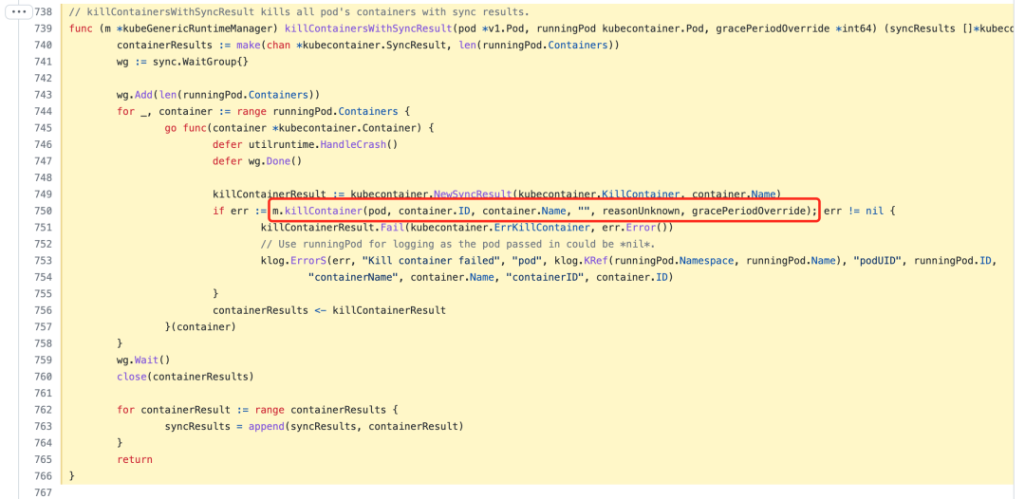
在这个函数中,使用多个 goroutine 来删除 Pod 中的每个容器。删除容器的方法是killContainer,在停止容器之前首先执行钩子预停止(如果存在),代码位于https://github.com/kubernetes/kubernetes/blob/v1.22.8/ pkg/kubelet/kuberuntime/kuberuntime_container.go#L660-L736。
首先得到优雅的删除宽限时间。
// From this point, pod and container must be non-nil.
gracePeriod := int64(minimumGracePeriodInSeconds)
switch {
case pod.DeletionGracePeriodSeconds != nil:
gracePeriod = *pod.DeletionGracePeriodSeconds
case pod.Spec.TerminationGracePeriodSeconds != nil:
gracePeriod = *pod.Spec.TerminationGracePeriodSeconds
switch reason {
case reasonStartupProbe:
if containerSpec.StartupProbe != nil && containerSpec.StartupProbe.TerminationGracePeriodSeconds != nil {
gracePeriod = *containerSpec.StartupProbe.TerminationGracePeriodSeconds
}
case reasonLivenessProbe:
if containerSpec.LivenessProbe != nil && containerSpec.LivenessProbe.TerminationGracePeriodSeconds != nil {
gracePeriod = *containerSpec.LivenessProbe.TerminationGracePeriodSeconds
}
}
}
在资源清单文件中哪里TerminationGracePeriodSeconds可以设置,默认是30秒,这个时间是,向Pod发送关机命令后会向应用程序发送SIGTERM信号,程序只需要捕获SIGTERM信号并做相应的处理即可。这是 Pod 收到 SIGTERM 信号后应用程序可以正常关闭的时间。这个时间是由前面分析过的apiserver设置的。
如果配置了 pre-stop hook 并且有足够的时间,hook 将被执行。pre-stop主要是为了让业务在容器被删除之前优雅的停止,比如资源回收等操作。

最后它实际上会去调用底层容器运行时来停止容器。
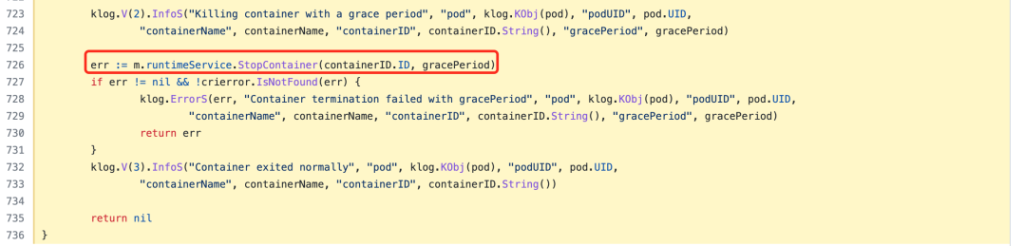
容器删除返回killPodWithSyncResult函数后,接下来就是调用StopPodSandbox运行时服务的函数来停止沙盒容器,也就是暂停容器。
// Stop all sandboxes belongs to same pod
for _, podSandbox := range runningPod.Sandboxes {
if err := m.runtimeService.StopPodSandbox(podSandbox.ID.ID); err != nil && !crierror.IsNotFound(err) {
killSandboxResult.Fail(kubecontainer.ErrKillPodSandbox, err.Error())
klog.ErrorS(nil, "Failed to stop sandbox", "podSandboxID", podSandbox.ID)
}
}
这是 kubelet 完成 Pod 的优雅移除的地方,但它并没有就此结束。
同步状态
对于优雅删除,一开始apiserver只是DeletionTimestamp给Pod设置了属性,然后更新了kubelet watch,完成了Pod的优雅删除,但是现在server端还有一条Pod的记录,而且是没有真正删除。
kubelet 启动的时候,也会启动一个 statusManager 同步循环,这是 kubelet pod 状态的真正来源,应该和最新的 v1.1 同步。manager 将状态同步回 apiserver。
状态管理器会调用管理器syncPod下面的方法来处理与 apiserver 的状态同步,它位于https://github.com/kubernetes/kubernetes/blob/v1.22.8/pkg/kubelet/status/status_manager.go #L149-L181。如下。
func (m *manager) Start() {
// Don't start the status manager if we don't have a client. This will happen
// on the master, where the kubelet is responsible for bootstrapping the pods
// of the master components.
if m.kubeClient == nil {
klog.InfoS("Kubernetes client is nil, not starting status manager")
return
}
klog.InfoS("Starting to sync pod status with apiserver")
//lint:ignore SA1015 Ticker can link since this is only called once and doesn't handle termination.
syncTicker := time.Tick(syncPeriod)
// syncPod and syncBatch share the same go routine to avoid sync races.
go wait.Forever(func() {
for {
select {
case syncRequest := <-m.podStatusChannel:
klog.V(5).InfoS("Status Manager: syncing pod with status from podStatusChannel",
"podUID", syncRequest.podUID,
"statusVersion", syncRequest.status.version,
"status", syncRequest.status.status)
m.syncPod(syncRequest.podUID, syncRequest.status)
case <-syncTicker:
klog.V(5).InfoS("Status Manager: syncing batch")
// remove any entries in the status channel since the batch will handle them
for i := len(m.podStatusChannel); i > 0; i-- {
<-m.podStatusChannel
}
m.syncBatch()
}
}
}, 0)
}
该方法判断 Pod 是否已经优雅停止,代码位于https://github.com/kubernetes/kubernetes/blob/v1.22.8/pkg/kubelet/status/status_manager.go#L583-L652。如下所示。
// We don't handle graceful deletion of mirror pods.
if m.canBeDeleted(pod, status.status) {
deleteOptions := metav1.DeleteOptions{
GracePeriodSeconds: new(int64),
// Use the pod UID as the precondition for deletion to prevent deleting a
// newly created pod with the same name and namespace.
Preconditions: metav1.NewUIDPreconditions(string(pod.UID)),
}
err = m.kubeClient.CoreV1().Pods(pod.Namespace).Delete(context.TODO(), pod.Name, deleteOptions)
if err != nil {
klog.InfoS("Failed to delete status for pod", "pod", klog.KObj(pod), "err", err)
return
}
klog.V(3).InfoS("Pod fully terminated and removed from etcd", "pod", klog.KObj(pod))
m.deletePodStatus(uid)
}
}
例如,它会判断是否还有容器在运行,是否还没有清理卷,是否还没有清空 pod cgroup,等等。如果canBeDeleted返回 true,则 pod 已经正常停止,因此您可以向 apiserver 发送 Delete 请求以再次删除该 pod。
但是,这次GracePeriodSeconds设置为0,表示该pod会被强制删除,此时apiserver会再次收到DELETE请求。和第一次不同的是,这一次是强制删除 Pod,将 Pod 对象从 etcd 中删除。
此时,kubelet 会收到 REMOVE 事件并调用该HandlePodRemoves函数进行处理。
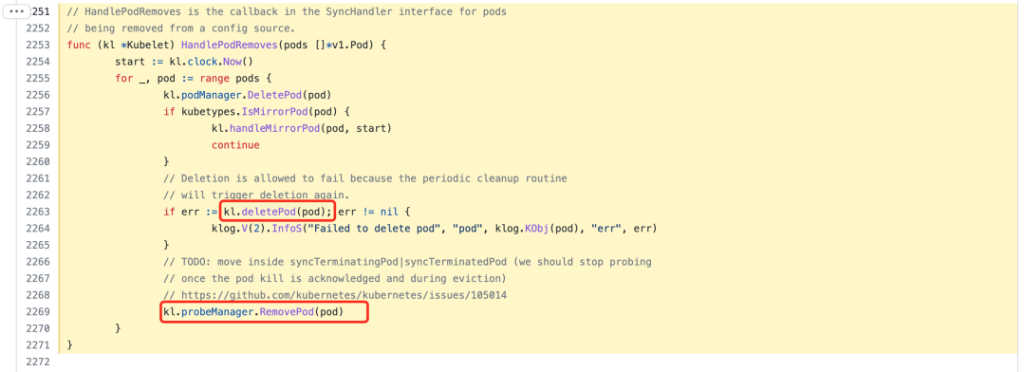
deletePod会先调用该函数停止关联的 pod worker,然后再调用该函数probeManager移除 pod 相关的probeprober worker,即该 pod 完全从节点中移除。
